
scrapyd部署总结
一、前言
由于毕设要做一个集成爬虫、文本分析和可视化的网站。需要将爬虫部署到网站上去供不懂技术的人使用。因此开始了研究scrapy+django。找了多方面的资料终于找到了我想要的,那就是scrapyd。网站通过http就可以从scrapyd上管理后台的爬虫了。
二、环境安装
安装scprayd,网址:https://github.com/scrapy/scrapyd
安装scrapyd-client,网址:https://github.com/scrapy/scrapyd-client
建议从github上下载最新源码,然后用python setup.py install安装,因为pip安装源有可能不是最新版的。
三、验证安装成功
在命令框中输入scrapyd,输出如下说明安装成功
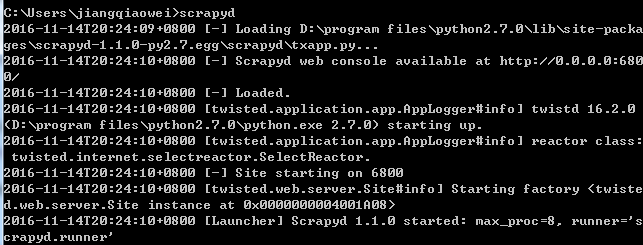
打开http://localhost:6800/ 可以看到

点击jobs可以查看爬虫运行情况。
接下来就是让人很头疼的scrapyd-deploy问题了,查看官方文档上说用
scrapyd-deploy -l
可以看到当前部署的爬虫项目,但是当我输入这段命令的时候显示这个命令不存在或者有错误、不合法之类的。
解决方案:
在你的python目录下的Scripts文件夹中,我的路径是“D:\program files\python2.7.0\Scripts”,增加一个scrapyd-deploy.bat文件。
内容为:
@echo off
"D:\program files\python2.7.0\python.exe" "D:\program files\python2.7.0\Scripts\scrapyd-deploy" %*
然后重新打开命令框,再运行scrapyd-deploy -l 就可以了。
四、发布工程到scrapyd
scrapyd-deploy <target> -p <project>
target为你的服务器命令,project是你的工程名字。
首先对你要发布的爬虫工程的scrapy.cfg 文件进行修改,我这个文件的内容如下:
[deploy:scrapyd1]
url = http://localhost:6800/
project = baidu
因此我输入的命令是:
scrapyd-deploy scrapyd1 -p baidu
输出如下

五、启动爬虫
使用如下命令启动一个爬虫
curl http://localhost:6800/schedule.json -d project=PROJECT_NAME -d spider=SPIDER_NAME
PROJECT_NAME填入你爬虫工程的名字,SPIDER_NAME填入你爬虫的名字
我输入的代码如下:
curl http://localhost:6800/schedule.json -d project=baidu -d spider=baidu

因为这个测试爬虫写的非常简单,一下子就运行完了。查看网站的jobs可以看到有一个爬虫已经运行完,处于Finished一列中
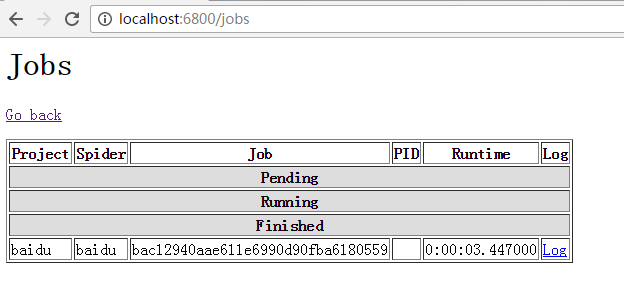
六、停止一个爬虫
curl http://localhost:6800/cancel.json -d project=PROJECT_NAME -d job=JOB_ID更多API可以查看官网:http://scrapyd.readthedocs.io/en/latest/api.html
七、远程开启服务器上的爬虫
代码如下:
# coding=utf-8
import urllib
import urllib2
# 启动爬虫
test_data = {'project':'baidu', 'spider':'baidu'}
test_data_urlencode = urllib.urlencode(test_data)
requrl = "http://localhost:6800/schedule.json"
# 以下是post请求
req = urllib2.Request(url = requrl, data = test_data_urlencode)
res_data = urllib2.urlopen(req)
res = res_data.read() # res 是str类型
print res
# 查看日志
# 以下是get请求
myproject = "baidu"
requrl = "http://localhost:6800/listjobs.json?project=" + myproject
req = urllib2.Request(requrl)
res_data = urllib2.urlopen(req)
res = res_data.read()
print res输出如下:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)