
MSCOCO数据集下载安装---image_caption
-下载安装MSCOCO2015的image_caption数据集,下载方式
【linux】
具体步骤:
1.$ git clone https://github.com/pdollar/coco.git
2.$ mkdir images $ mkdir annotations
3.根据需求在http://cocodataset.org/#download下载需要的,unzip解压放在以上目录里
此处使用2014年caption,82783train,40504val, 40775testimages///【查看文件数目:http://www.jb51.net/article/56474.htm】然后安装pythoncocoapi接口
4.$ cd PythonAPI
5.$ make
6.$ python $ import pycocotools不报错,即安装成功。
安装完成。
coco数据集的注释数据是以json格式存储的,coco很贴心的配置了数据读取的API。COCO API帮助加载、解析和可视化COCO中的注释。该API支持对象实例、对象关键点和图像标题注释(用于说明并非所有功能都已定义)。
7.写一个image_caption的demo.py
官方给的使用方法在下载目录下的pycocoDemo.ipynb文件下,包括了object detection, segmentation, person keypoints detection, stuff segmentation, and caption generation几种对于不同数据集的不同调用方式。此处我们只看imagecaption的调用方式:
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
dataDir='/pytorch/image_caption/coco'
dataType='val2014'
# initialize COCO api for caption annotations\n",
annFile = '{}/annotations/captions_{}.json'.format(dataDir,dataType)
coco=COCO(annFile)
catIds = coco.getCatIds(catNms=['person','dog','skateboard'])
imgIds = coco.getImgIds(catIds=catIds )
imgIds = coco.getImgIds(imgIds = [324158])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
# load and display caption annotations\n",
annIds = coco.getAnnIds(imgIds=img['id'])
anns = coco.loadAnns(annIds)
coco.showAnns(anns)运行报错:
catIds = coco.getCatIds(catNms=['person','dog','skateboard'])
File "/us。。un/anaconda3/lib/python3.6/site-packages/pycocotools/coco.py", line 172, in getCatIds
cats = self.dataset['categories']
KeyError: 'categories'需要注意到:
pycocotools/coco.py文件下已声明:
使用API的另一种方法是直接将注释加载到Python字典中。
使用API提供了额外的实用功能。
注意,这个API同时支持*instance*和*caption*的annotations。
在captions的情况下,不是所有的函数都被定义了(例如,categories 是没有定义的)。# getAnnIds -获得满足给定筛选条件的annotations id。
# getCatIds -获取满足给定筛选条件的categories id。
# getImgIds -获取满足给定筛选条件的imges id。 # loadAnns -加载指定id的anns。
# loadCats -装载指定id的cats。
# loadImgs -装载指定id的imgs。
所以对于caption来说,我们不使用getCatIds和loadCats。
所以demo.py修改如下
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
dataDir='/pytorch/image_caption/coco'
dataType='val2014'
# initialize COCO api for caption annotations\n",
annFile = '{}/annotations/captions_{}.json'.format(dataDir,dataType)
coco=COCO(annFile)
imgIds = coco.getImgIds(imgIds = [324158])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
# load and display caption annotations\n",
annIds = coco.getAnnIds(imgIds=img['id'])
anns = coco.loadAnns(annIds)
coco.showAnns(anns)完成。
其他参数暂做记载:
# decodeMask - Decode binary mask M encoded via run-length encoding.
# encodeMask - Encode binary mask M using run-length encoding.
# annToMask - Convert segmentation in an annotation to binary mask.
# loadRes - Load algorithm results and create API for accessing them.
# download - Download COCO images from mscoco.org server.
# Throughout the API "ann"=annotation, "cat"=category, and "img"=image.
# Help on each functions can be accessed by: "help COCO>function".8. eval方式
https://github.com/tylin/coco-caption/blob/master/cocoEvalCapDemo.ipynb
【windows】步骤: https://www.jianshu.com/p/de455d653301
【ref】请访问http://cocodataset.org/获取更多关于COCO的信息,包括数据、论文和教程;
请参见http://cocodataset.org/download 查看有关API的详细信息。
下载MSCOCO2015的image_caption参考http://blog.csdn.net/happyhorizion/article/details/77894205#coco
http://blog.csdn.net/daniaokuye/article/details/78699138(附代码)
http://blog.csdn.net/u012905422/article/details/52372755#reply
一篇很好的文章https://zhuanlan.zhihu.com/p/22408033(上)
https://zhuanlan.zhihu.com/p/22520434(下)===以下来自于该链接内容
1. 对于image-caption,CNN-RNN大同小异,差别在于更好的CNN以及lstm等。
2. 输入图像进入CNN,输出为Vatt(I)向量,其长度为标签集合中标签的数量(也就是词汇表的数量)(每个维度上装的是某个标签对应的预测概率),输入到RNN。
3. Vatt(I)是否仅在RNN开始时输入?还是每一t都输入?有论文验证当每一t都输入的情况下会造成图像噪点和过拟合问题。
4. 属性预测部分:该论文,我个人感到最有价值的部分,还是在它的图像分析部分中如何从图像到属性的实现,这是它的核心创新点
9.使用torchvision调用的方法
https://pypi.python.org/pypi/torchvision/0.1.8
Example:
import torchvision.datasets as dset
import torchvision.transforms as transforms
cap = dset.CocoCaptions(root = 'dir where images are',
annFile = 'json annotation file',
transform=transforms.ToTensor())
print('Number of samples: ', len(cap))
img, target = cap[3] # load 4th sample
print("Image Size: ", img.size())
print(target)
Output:
Number of samples: 82783
Image Size: (3L, 427L, 640L)
[u'A plane emitting smoke stream flying over a mountain.',
u'A plane darts across a bright blue sky behind a mountain covered in snow',
u'A plane leaves a contrail above the snowy mountain top.',
u'A mountain that has a plane flying overheard in the distance.',
u'A mountain view with a plume of smoke in the background']pytorch源码:https://github.com/pytorch/vision/blob/master/torchvision/datasets/coco.py
以下内容用于在无法fanqiang时 进行学习:http://cocodataset.org/#download 下的内容:
Tools
Images
2014 Train images [83K/13GB]
2014 Val images [41K/6GB]
2014 Test images [41K/6GB]
2015 Test images [81K/12GB]
2017 Train images [118K/18GB]
2017 Val images [5K/1GB]
2017 Test images [41K/6GB]
2017 Unlabeled images [123K/19GB]
Annotations
2014 Train/Val annotations [241MB]
2014 Testing Image info [1MB]
2015 Testing Image info [2MB]
2017 Train/Val annotations [241MB]
2017 Stuff Train/Val annotations [401MB]
2017 Testing Image info [1MB]
2017 Unlabeled Image info [4MB]
1. Overview
Which dataset splits should you download? Each year's split is associated with different challenges. Specifically:
2014 Train/Val
Detection 2015, Captioning 2015, Detection 2016, Keypoints 2016
2014 Testing
2015 Testing
Detection 2015, Detection 2016, Keypoints 2016
2017 Train/Val
Detection 2017, Keypoints 2017, Stuff 2017
2017 Testing
Detection 2017, Keypoints 2017, Stuff 2017
2017 Unlabeled
[optional data for any competition]
If you are submitting to a 2017 challenge, you only need to download the 2017 data. You can disregard earlier data splits.
For efficiently downloading the images, we recommend using gsutil rsync to avoid the download of large zip files.
Please follow the instructions in the COCO API Readme to setup the downloaded COCO data (the images and annotations). By downloading this dataset, you agree to our Terms of Use.
2017 Update: The main change in 2017 is that instead of an 80K/40K train/val split, based on community feedback the split is now 115K/5K for train/val. The same exact images are used, and no new annotations for detection/keypoints are provided. However, new in 2017 are stuff annotations on 40K train images (subset of the full 115K train images from 2017) and 5K val images. Also, for testing, in 2017 the test set only has two splits (dev / challenge), instead of the four splits (dev / standard / reserve / challenge) used in previous years. Finally, new in 2017 we are releasing 120K unlabeled images from COCO that follow the same class distribution as the labeled images; this may be useful for semi-supervised learning on COCO.
Note: Annotations last updated 09/05/2017 (stuff annotations added). If you find any issues with the data please let us know!
2. COCO API
The COCO API assists in loading, parsing, and visualizing annotations in COCO. The API supports object instance, object keypoint, and image caption annotations (for captions not all functionality is defined). For additional details see: CocoApi.m, coco.py, and CocoApi.lua for Matlab, Python, and Lua code, respectively, and also the Python API demo.
Throughout the API "ann"=annotation, "cat"=category, and "img"=image.
download
Download COCO images from mscoco.org server.
getAnnIds
Get ann ids that satisfy given filter conditions.
getCatIds
Get cat ids that satisfy given filter conditions.
getImgIds
Get img ids that satisfy given filter conditions.
loadAnns
Load anns with the specified ids.
loadCats
Load cats with the specified ids.
loadImgs
Load imgs with the specified ids.
loadRes
Load algorithm results and create API for accessing them.
showAnns
Display the specified annotations.
3. MASK API
COCO provides segmentation masks for every object instance. This creates two challenges: storing masks compactly and performing mask computations efficiently. We solve both challenges using a custom Run Length Encoding (RLE) scheme. The size of the RLE representation is proportional to the number of boundaries pixels of a mask and operations such as area, union, or intersection can be computed efficiently directly on the RLE. Specifically, assuming fairly simple shapes, the RLE representation is O(√n) where n is number of pixels in the object, and common computations are likewise O(√n). Naively computing the same operations on the decoded masks (stored as an array) would be O(n).
The MASK API provides an interface for manipulating masks stored in RLE format. The API is defined below, for additional details see: MaskApi.m, mask.py, or MaskApi.lua. Finally, we note that a majority of ground truth masks are stored as polygons (which are quite compact), these polygons are converted to RLE when needed.
encode
Encode binary masks using RLE.
decode
Decode binary masks encoded via RLE.
merge
Compute union or intersection of encoded masks.
iou
Compute intersection over union between masks.
area
Compute area of encoded masks.
toBbox
Get bounding boxes surrounding encoded masks.
frBbox
Convert bounding boxes to encoded masks.
frPoly
Convert polygon to encoded mask.
4. Annotation format
COCO currently has three annotation types: object instances, object keypoints, and image captions. The annotations are stored using the JSON file format. All annotations share the basic data structure below:
{
"info"
: info,
"images"
: [image],
"annotations"
: [annotation],
"licenses"
: [license],
}
info{
"year"
: int,
"version"
: str,
"description"
: str,
"contributor"
: str,
"url"
: str,
"date_created"
: datetime,
}
image{
"id"
: int,
"width"
: int,
"height"
: int,
"file_name"
: str,
"license"
: int,
"flickr_url"
: str,
"coco_url"
: str,
"date_captured"
: datetime,
}
license{
"id"
: int,
"name"
: str,
"url"
: str,
}
The data structures specific to the various annotation types are described below.
4.4. Image Caption Annotations
These annotations are used to store image captions. Each caption describes the specified image and each image has at least 5 captions (some images have more). See also the Captioning Challenge.
annotation{
"id"
: int,
"image_id"
: int,
"caption"
: str,
}
http://cocodataset.org/#captions-eval下内容
1. Caption Evaluation
This page describes the caption evaluation code used by COCO and provides instructions for submitting results to the evaluation server. The evaluation code provided here can be used to obtain results on the publicly available COCO validation set. It computes multiple common metrics, including BLEU, METEOR, ROUGE-L, and CIDEr (the writeup below contains references and descriptions of each metric). If you use the captions, evaluation code, or server, we ask that you cite Microsoft COCO Captions: Data Collection and Evaluation Server:
@article{capeval2015,
Author={X. Chen and H. Fang and TY Lin and R. Vedantam and S. Gupta and P. Dollár and C. L. Zitnick},
Journal = {arXiv:1504.00325},
Title = {Microsoft COCO Captions: Data Collection and Evaluation Server},
Year = {2015}
}
To obtain results on the COCO test set, for which ground truth annotations are hidden, generated results must be submitted to the evaluation server. The exact same evaluation code, described below, is used to evaluate generated captions on the test set.
2. Evaluation Code
Evaluation code can be obtained on the coco-captions github page. Unlike the general COCO API, the COCO caption evaluation code is only available under Python. Before running the evaluation code, please prepare your results in the format described on the results format page.
Running the evaluation code produces two data structures that summarize caption quality. The two structs are evalImgsand eval, which summarize caption quality per-image and aggregated across the entire test set, respectively. Details for the two data structures are given below. We recommend running the python caption evaluation demo for more details.
evalImgs[{
"image_id"
: int,
"BLEU_1"
: float,
"BLEU_2"
: float,
"BLEU_3"
: float,
"BLEU_4"
: float,
"METEOR"
: float,
"ROUGE_L"
: float,
"CIDEr"
: float,
}]
eval{
"BLEU_1"
: float,
"BLEU_2"
: float,
"BLEU_3"
: float,
"BLEU_4"
: float,
"METEOR"
: float,
"ROUGE_L"
: float,
"CIDEr"
: float,
}
3. Upload Results
This rest of this page describes the upload instructions for submitting results to the caption evaluation server. Submitting results allows you to participate in the COCO Captioning Challenge 2015 and compare results to the state-of-the-art on the captioning leaderboard.
Training Data: The recommended training set for the captioning challenge is the COCO 2014 Training Set. The COCO 2014 Validation Set may also be used for training when submitting results on the test set. External data of any form is allowed (except any form of annotation on the COCO Testing set is forbidden). Please specify any and all external data used for training in the "method description" when uploading results to the evaluation server.
Please limit the number of entries to the captioning challenge to a reasonable number, e.g. one entry per paper. To avoid overfitting to the test data, the number of submissions per user is limited to 1 upload per day and a maximum of 5 submissions per user. It is not acceptable to create multiple accounts for a single project to circumvent this limit. The exception to this is if a group publishes two papers describing unrelated methods, in this case both sets of results can be submitted for evaluation.
First you need to create an account on CodaLab. From your account you will be able to participate in all COCO challenges.
Before uploading your results to the evaluation server, you will need to create two JSON files containing your captioning results in the correct results format. One file should correspond to your results on the 2014 validation dataset, and the other to the 2014 test dataset. Both sets of results are required for submission. Your files should be named as follows:
results.zip
captions_val2014_[alg]_results.json
captions_test2014_[alg]_results.json
Replace [alg] with your algorithm name and place both files into a single zip file named "results.zip".
To submit your zipped result file to the COCO Captioning Challenge click on the “Participate” tab on the CodaLab webpage. When you select “Submit / View Results” you will be given the option to submit new results. Please fill in the required fields and click “Submit”. A pop-up will prompt you to select the results zip file for upload. After the file is uploaded the evaluation server will begin processing. To view the status of your submission please select “Refresh Status”. Please be patient, the evaluation may take quite some time to complete. If the status of your submission is “Failed” please check to make sure your files are named correctly, they have the right format, and your zip file contains two files corresponding to the validation and testing datasets.
After you submit your results to the evaluation server, you can control whether your results are publicly posted to the CodaLab leaderboard. To toggle the public visibility of your results please select either “post to leaderboard” or “remove from leaderboard”. For now only one result can be published to the leaderboard at any time, we may change this in the future. After your results are posted to the CodaLab leaderboard, your captions on the validation dataset will be publicly available. Your captions on the test set will not be publicly released.
In addition to the CodaLab leaderboard, we also host our own more detailed leaderboard that includes additional results and method information (such as paper references). Note that the CodaLab leaderboard may contain results not yet migrated to our own leaderboard.
After evaluation is complete and the server shows a status of “Finished”, you will have the option to download your evaluation results by selecting “Download evaluation output from scoring step.” The zip file will contain five files:
captions_val2014_[alg]_evalimgs.json
captions_val2014_[alg]_eval.json
captions_test2014_[alg]_eval.json
metadata
scores.txt
% per image evaluation on val
% aggregated evaluation on val
% aggregated evaluation on test
% auto generated (safe to ignore)
% auto generated (safe to ignore)
The format of the json eval file is described earlier on this page. Please note that the *_evalImgs.json file is only available for download on the validation dataset, and not the test set.
http://cocodataset.org/#external下内容
External Annotations on COCO and Related Datasets
Please contact us to add your dataset here! Do not release annotations on test set images under any circumstances to keep the integrity of the COCO challenges intact (contact us with any questions). Note: the following datasets may use COCO data but are independent efforts not directly affiliated with COCO.

COCO-Stuff augments the COCO dataset with pixel-level stuff annotations for 10,000 images. The 91 stuff classes are carefully selected to have a similar level of granularity to the thing classes in COCO, allowing the study of stuff and things in context.

Don't be foiled: Detect the mistake and correct it! FOIL augments COCO images with incorrect ('foil') captions which differ from the original ones by introducing one single error. The dataset contains ~300K datapoints and 98K unique images.
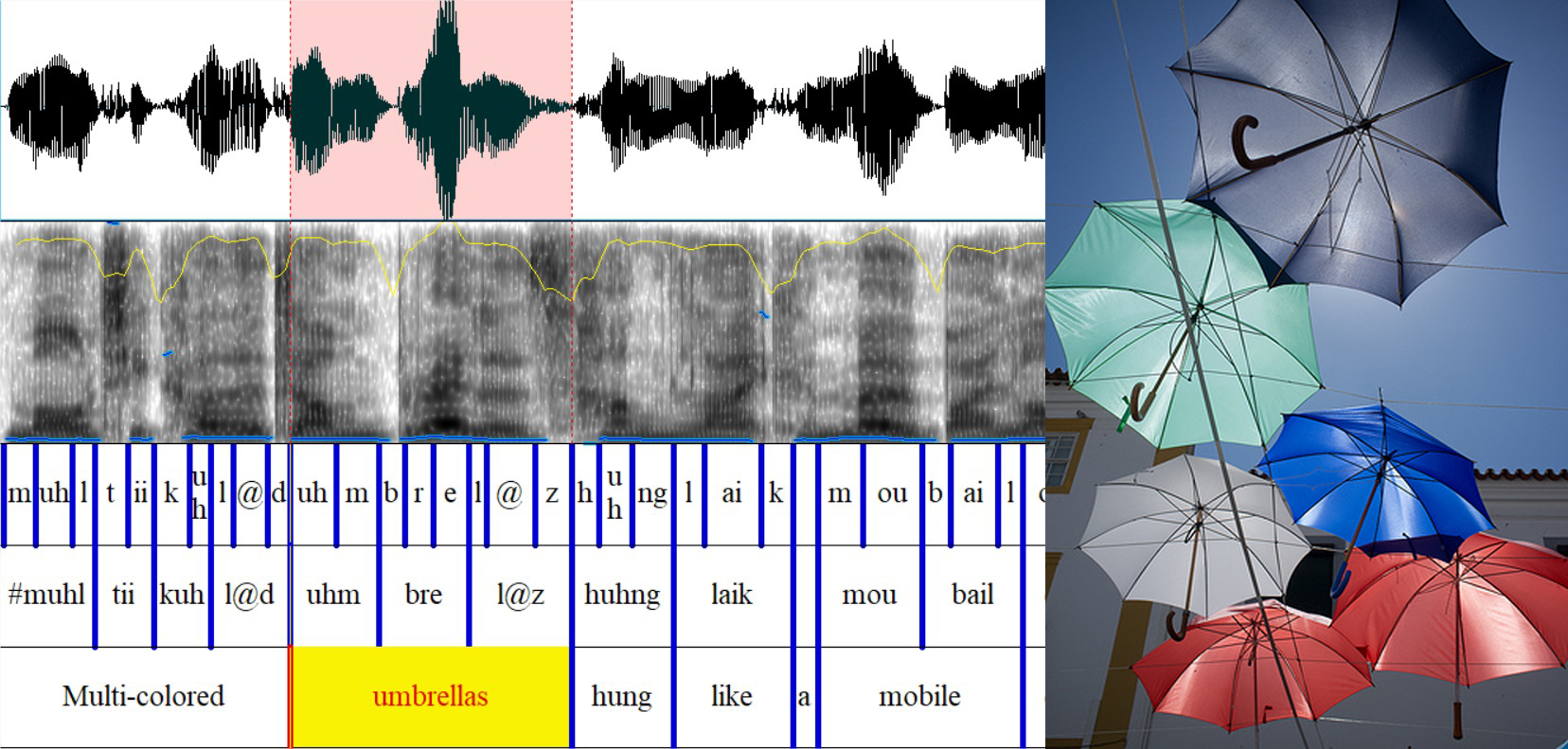
SPEECH-COCO augments COCO with speech captions generated using TTS synthesis. The corpus contains 600K+ spoken captions, allowing research of language acquisition, term discovery, keyword spotting, or semantic embedding using speech and vision.
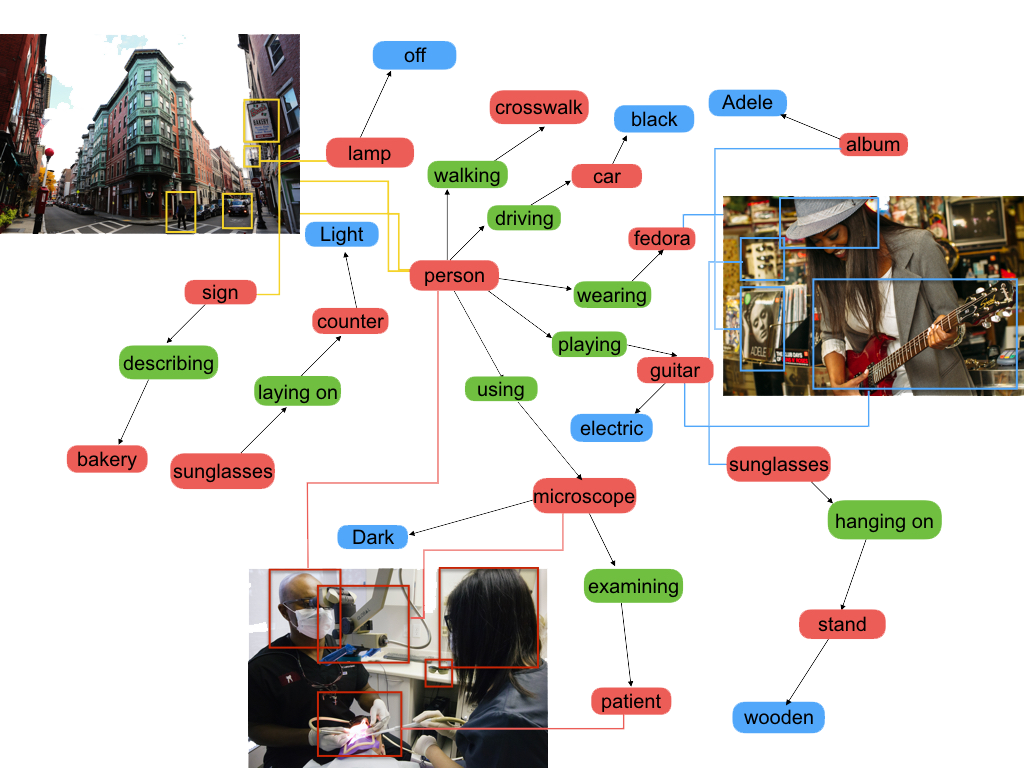
Visual Genome is a dataset, a knowledge base, an ongoing effort to connect structured image concepts to language.

RefCOCO dataset was collected using the Refer-it Game. Each expression aims to unambiguously indicate a particular person or object in an image.

COCO Attributes has over 3.5M attribute annotations for People, Animals, and Objects from the COCO training dataset.

Google referring expression dataset (G-Ref) is a dataset focuses on unambiguous object text descriptions (i.e. referring expressions) that allow one to uniquely identify a single object or region within an image.

VerSe annotates COCO images with OntoNotes senses for 90 verbs (actions) which have ambiguous visual usages. Along with the sense information we provide visualness labels for OntoNotes senses of 150 visual verbs.
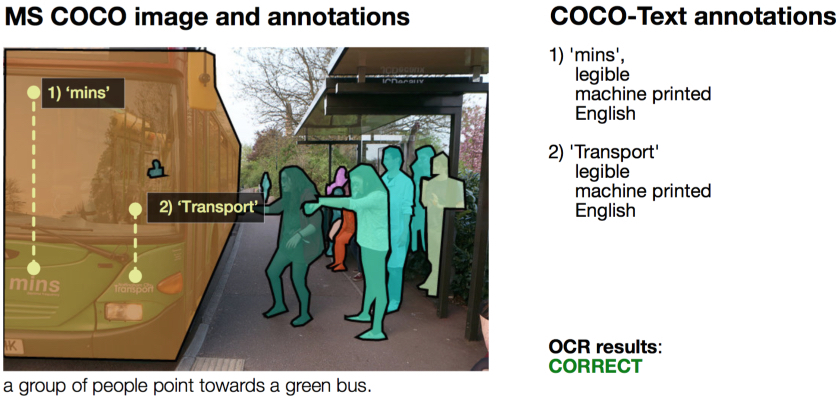
COCO-Text is for both text detection and recognition. The dataset annotates scene text with transcriptions along with attributes such as legibility, printed or handwritten text.

The Freestyle Multilingual Image Question Answering (FM-IQA) dataset contains over 120,000 images and 250,000 freestyle Chinese question-answer pairs and their English translations.

VQA is a new dataset containing open-ended questions about images. These questions require an understanding of vision, language and commonsense knowledge to answer.

Visual Madlibs is a new dataset consisting of focused natural language descriptions collected using automatically produced fill-in-the-blank templates. This dataset can be used for targeted generation or multiple-choice question-answering.

COCO-a annotates human actions and interactions with objects (or other people) with 140 visual actions (verbs with an unambiguous visual connotation), along with information such as emotional state and relative distance and position with the object.

The SALICON dataset offers a large set of saliency annotations on the COCO dataset. This data complements the task-specific annotations to advance the ultimate goal of visual understanding.

Annotations for PASCAL VOC 2007 and 2012 in COCO format. This allows use of the PASCAL detection data with the COCO API (including visualization and evaluation tools). JSON available here.

Annotations for ImageNet 2014 train/val in COCO format. This allows use of the ImageNet detection data with the COCO API (including visualization and evaluation tools). JSON available here.

YOUR DATASET
Please contact us to add your dataset here! Do not release annotations on the test-set images under any circumstances to keep the integrity of the COCO challenges intact (please contact us with any questions if in doubt)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)